游戏中通常会用到许多数据,一种是玩家在游戏过程中产生的数据,通常这些数据会被存储到数据库端,客户端需要远程拉取;另一种是设计者为玩家预先设置好的数据,这些数据构建出了整个游戏世界,而且不以玩家实时行为为转移,每一份这种数据都是对游戏某一方面或者某一特性做出的一种描述。本文主要关心的话题是后者,介绍我在游戏开发过程中实现的一套表格数据配置系统。
技术选型
1. 序列化技术
通常序列化技术模型可以分为关系模型和非关系模型。举个例子,采用非关系模型的序列化技术比如xml、JSON等,关系模型的序列化技术比如excel。
那么什么是关系模型呢?关系模型全称关系数据模型,它是以数学中集合论中的关系概念为基础发展起来的。关系模型无论是实体还是实体间的联系均由单一的结构类型——关系来表示。
以下为两种模型的特性及优缺点。
| 类型 | 特性 | 优点 | 缺点 |
|---|---|---|---|
| 关系模型 | 二维表格模型 | 1. 容易理解:二维表结构是非常贴近逻辑世界一个概念,关系模型相对网状、层次等其他模型来说更容易理解; 2. 易于维护:数据完整性大大降低了数据冗余和数据不一致的概率; 3. 二维结构易于批量处理数据; |
1. 为了维护完整性,读写数据量变大; 2. 固定的表结构; |
| 非关系模型 | 键值对存储数据 | 1. 基于键值对的存储方式,使数据没有耦合性,容易扩展; 2. 数据不用维护完整性,数据量相对较小,适用于保存海量数据 |
1. 结构复杂,阅读成本高; 2. 难于批量处理数据; |
在Unity里面,大部分可序列化对象都最终会以非关系模型来保存数据,比如预制体对象(.prefab)、材质对象(.mat)。思考一个问题,如果要批量修改预制体怎么办?也许就需要写一段Editor代码去实现批量操作,成本非常高。再思考一个问题,怎么去阅读一个预制体里的内容?显然直接打开一个文本很不直观,就需要有图形化界面去显示每一个对象的数据。由于设计和数据模型特性,Unity使用非关系模型序列化数据没问题,但是如果要在成本可控范围内去让策划更方便地维护数据,非关系模型显然成本太高。所以本文主要采用关系模型,即Excel表格。
2. Excel类型
通常使用Excel的思路有两种:1. 使用电子表格格式(.xls/.xlsx工作表);2. 使用CSV格式。其中CSV格式由于分隔符不同,分为tab分隔符和逗号分隔符两种格式。
首先来说这两种Excel格式都是被业内比较普遍的使用的,接下来介绍一下两种格式的不同点。
2.1 电子表格格式(.xls/.xlsx工作表)
电子表格格式作为一种二进制格式,通常需要专门的解析工具才能读取文件中的内容。但是如果将其直接应用到游戏里,也就是说将xls直接解析读取到内存中,将会得到很多冗余的信息,浪费内存。因此业内普遍做法如下图所示。
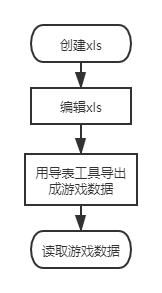
优点:
- 由于源文件使用xls格式,所以Excel的内部单元格信息得以保存下来,比如设置某一格的颜色,以及对某一格的注释。
- 导表工具如果直接导出成代码里对应类的结构,并保存成二进制,加载的时候省去了很多解析的过程,很小程度上对提升加载速度和较小包体有帮助。
缺点:
- 编辑完表格还需要把表格转成游戏数据,工作步骤繁复且容易遗忘。
- 配合项目版本管理软件,无法做到解决冲突,冲突时只能全部覆盖替换。
2.2 CSV格式
CSV格式本质上就是文本文件,因此CSV格式文本不需要专门的解析工具即可读取文件中的内容。CSV格式有两种,需要注意的是,逗号分隔符的CSV格式通常为UTF-8编码格式,tab分隔符的CSV格式通常为Unicode编码方式(2字节存储)。
首先分析一下CSV格式和电子表格格式优缺点。
优点:
- 无需转表,游戏可以直接读取文本,简化工作流程,提升团队工作效率。
- 便于版本管理,遇到冲突可以从容解决。
缺点:
- xls内部单元格信息无法保存下来,比如要给某一格上色、冻结某一行或者加注释都是无法实现的。
- 游戏加载时候需要写解析逻辑,要把字符串转为对应数据,很小程度上增加加载时间。
其次分析一下两种CSV的优缺点。
- 逗号分隔符的CSV格式:很多时候游戏数据里就会有逗号,很容易跟分隔符的逗号产生歧义,增加解析风险,增加编辑难度。
- tab分隔符的CSV格式:2字节存储浪费空间。
2.3 综合分析
- 表格单元格信息其实可有可无,有时候太多太复杂的单元格信息,反而会让表格排版变得混乱、不清洁
- 简化工作流程,提升团队工作效率,在项目量级越大越能体现出其优势
综合分析,作者更偏爱使用tab格式的CSV格式来存储游戏数据。本文也重点探讨一种使用tab格式的CSV格式来存储游戏数据的方案。
实现
1. 概览
为了实现一套基于CSV格式的表格配置系统,可以把系统分为以下四个模块:表格数据模块、表格加载模块、表格解析模块、表格编辑器模块。
2. 表格数据模块
该模块根据游戏所有的数据类型分别定义了其对应的数据结构体,该结构体保存了该数据类型所有的数据字段,并对应着一张数据表格。比如角色数据结构体,对应着一张数据表格,其数据信息包括角色ID、角色资源路径、角色种族、角色名字等。
每个数据类型都包含一个主键字段,主键字段要求对于该数据类型必须全局唯一,游戏中可以通过主键去索引到某一条数据。比如在角色数据里,角色ID就是该类型的主键,通过角色ID,可以很容易找到一个角色的所有信息。
在Unity代码里,所有数据类型都继承于ExcelBase<T, U>,其中T为其实现类类型本身,U为主键类型。这里可能有点绕,T为什么会是其实现类类型本身?因为我们不想为每个实现类在写一个管理类去管理该实现类的所有对象,通过实现类自身的静态方法就可以去管理和访问子类所有对象。
代码如下。
public class ExcelBase<T, U> where T : IExcelLine<U>
{
public static void Add(T excel) ...
public static void Remove(U id) ...
public static T Find(U id) ...
public static Dictionary<U, T>.Enumerator GetEnumerator() ...
public static void Clear() ...
public static Dictionary<U, T> excelView;
}
由代码可见,每一个数据类型同时是自己的管理者。例如角色数据类型的代码如下。
public class excel_cha_list : ExcelBase<excel_cha_list, int>, IExcelLine<int>
{
public int id;
public string name;
public int type;
public int race;
public string path;
public float halfSize;
public string portrait;
public int GetPrimaryKey()
{
return id;
}
}
如果想要增加一个角色数据怎么办?
excel_cha_list chaList = new excel_cha_list();
chaList.id = 1001;
chaList.name = "Arthas";
chaList.type = CharacterType.NPC;
chaList.race = CharacterRace.Undead;
excel_cha_list.Add(chaList);
通过上述代码,我们就成功添加了一个角色,该角色为一个名为阿尔萨斯的不死族NPC,ID为1001。
再比如,如果想要查找一个角色怎么办?
excel_cha_list chaList = excel_cha_list.Find(1001);
通过上述代码,我们就成功取到ID为1001的角色的角色信息了。
3. 表格加载模块
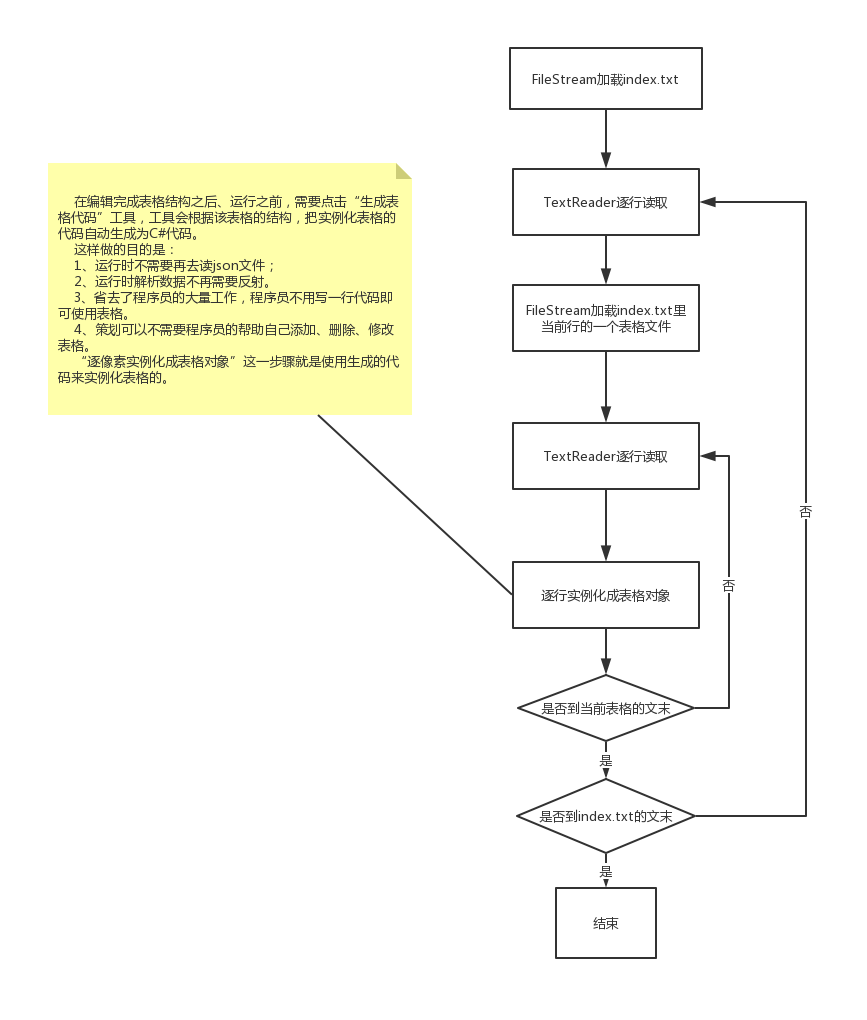
如上图所示,加载方式其实很简单,就是逐行读取文本内容,再把每一行文字用tab分隔符分成多段文字,再根据数据格式去解析每一个数据。最终就解析成许多个ExcelBase<T, U>的集合。图中所说自动生成代码将在后续介绍。
4. 表格解析模块
表格解析模块主要是ExcelFactory这个类,该类包含了若干个解析器,比如整形数字解析器、浮点型数组解析器、字符串解析器等,同时也包括对这些解析类型的序列化方法。
当加载模块加载完每一条数据,就会调用解析模块的对应解析器去生成对应类型数据,并保存在excelView这个数据集合中。
思考一个问题,解析的时候,当代码解析cha_list.txt时,如何知道cha_list.txt对应的类型就是excel_cha_list呢?
可能会说用反射不就可以知道了吗,确实反射没问题,但是反射会带来一些性能上的开销,这个开销原本是可以避免的。
因此这里没有使用反射机制,而是将类型和文件名做一个绑定,并注册这个绑定关系(包含一组解析器的解析过程)到ExcelFactory中,例如当程序解析到cha_list.txt时,它就知道用excel_cha_list类的规则来进行解析。
这里又会产生一个问题,如果每一个类型都要手动去注册一个绑定关系,那开发成本会不会太高?
为了解决这个问题,系统就得实现一套自动化代码生成工具,避免去手写这些解析过程。
根据关系数据类型的完整性,表格里每一列数据都需要有一个确定的数据类型,可以是整数,也可以是浮点数等。一些表格的做法是直接在表头上把数据类型也表示出来。这里会使用另一个配置文件来阐述表格数据类型,就不再复杂化表格本身了。
在系统中,每个表格将会对应一个阐述其每一列数据类型的json配置文件,例如角色表格cha_list.txt如下。

同时存在一个名为cha_list.json的配置文件,内容如下。
{
"fields": [
{ "name": "id", "type": "int" },
{ "name": "name", "type": "string" },
{ "name": "type", "type": "int" },
{ "name": "race", "type": "int" },
{ "name": "path", "type": "string" },
{ "name": "halfSize", "type": "float" },
{ "name": "portrait", "type": "string" }
],
"files": [
"cha/cha_list"
],
"primaryKey": "id"
}
该配置文件主要分为以下三个部分:
- fields:描述每一个字段(列)的数据名和数据类型。
- files:该类型数据分别保存在哪几张表格里,这里提供了分表的可能性,就是同样的数据可以分别配置在不同txt中,只要主键不重复就是合法的。
- primaryKey:主键的数据名。
当开发人员定义好一张表格与一张配置表后,点击一键生成代码,就会通过表格编辑器模块生成该类型数据的解析过程代码。
如此就解决了
- 解析去反射
- 自动化生成解析代码
5. 表格编辑器模块
该模块主要就是为了生成解析代码而存在,功能和用法已经在上文讲述过不再赘述。
总结
该系统解决了以下问题
- 无需转表,游戏可以直接读取文本,简化工作流程,提升团队工作效率。
- 便于版本管理,遇到冲突可以从容解决。
- 设计人员可以使用分表功能,来防止编辑内容冲突。
- 简洁易用的代码风格。
- 解析去反射,并且自动生成代码。