渲染技术总是伴随着显卡硬件的升级而发展的,从最初的GeForce 256开始支持T&L,到RTX支持光追,硬件和渲染技术都在不断更新。作为软件技术开发人员,平时更多是从软件视角去理解渲染。为了更进一步了解渲染的本质,本文换一个视角,收集并整理了一些资料,从GPU架构的角度来重新了解一下渲染。
GPU架构
GPU概括来讲,就是由显存和许多计算单元组成。
显存(Global Memory)主要指的是在GPU主板上的DRAM,类似于CPU的内存,特点是容量大但是速度慢,CPU和GPU都可以访问。
计算单元通常是指SM(Stream Multiprocessor,流多处理器),这些SM在不同的显卡上组织方式还不太一样。作为执行计算的单元,其内部还有自己的控制模块、寄存器、缓存、指令流水线等部件。

计算单元
下面是Maxwell架构图和Turing架构图。


从Fermi开始NVIDIA使用类似的原理架构。
GPU包含若干个GPC(Graphics Processing Cluster,图形处理簇),不同架构的GPU包含的GPC数量不一样。例如Maxwell由4个GPC组成;Turing由6个GPC组成。
GPC包含若干个SM(Stream Multiprocessor,流多处理器),不同架构的GPU的GPC包含的SM数量不一样。例如Maxwell的一个GPC有4个SM;而Turing的一个GPC包含了6个TPC(Texture/Processor Cluster,纹理处理簇),每个TPC又包含了2个SM。
补充:GPC里除了有SM还有一些其它的部件,比如光栅化引擎(Raster Engine)。另外,连接每个GPC靠的是Crossbar,例如某一个GPC计算完的数据需要另外GPC来处理,这个分配就是靠的Crossbar。
这里的SM就是本章节所说的计算单元,同时需要知道的是,程序员平时写的Shader就是在SM上进行处理的。
SM(Stream Multiprocessor,流多处理器)
不同GPU厂商的架构中,SM的叫法不尽相同。
-
高通称作Streaming Processor / Shder Processor。
-
Mali称作Shader Core。
-
PowerVR称作Unified Shading Cluster,通常简称为Shading Cluster或USC。
-
ATI/OpenCL称作Compute Unit,通常简称为CU。
下图展示了一个SM的内部结构。
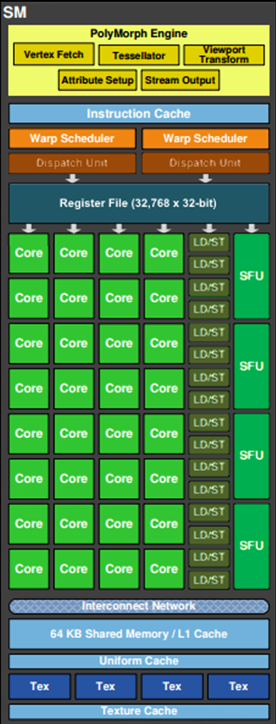
以Fermi架构的单个SM来说,其包含以下部件。
-
PolyMorph Engine:多边形变形引擎。负责处理和多边形顶点相关的工作,包括以下模块。
-
Vertex Fetch模块:顶点处理前期的通过三角形索引取出三角形数据。
-
Tesselator模块:对应着DX11引入的新特性曲面细分。
-
Stream Output模块:对应着DX10引入的新特性Stream Output。
-
Viewport Transform模块:对应着顶点的视口变换,三角形会被裁剪准备栅格化。
-
Attribute Setup模块:负责顶点的插值运算并输出给后续像素处理阶段使用。
-
-
Core:运算核心,也叫流处理器(SP——Stream Processor)。每个SM由32个运算核心组成。由Warp Scheduler调度,接收Dispatch Units的指令并执行,下面会详细介绍。
-
Warp Schedulers:Warp调度模块。Warp的概念其实就是一组线程,通常由32个线程组成,对应着32个运算核心。Warp调度器的指令通过Dispatch Units送到运算核心(Core)执行。
-
Instruction Cache:指令缓存。存放将要执行的指令,通过Dispatch Units填装到每个运算核心(Core)进行运算。
-
SFU:特殊函数单元(Special function units)。与Adreno GPU中的初等函数单元(Elementary Function Unit,EFU)类似,执行特殊数学运算。由于其数量少,在高级数学函数使用较多时有明显瓶颈。特殊函数例如以下几类。
-
幂函数:pow(x, a)、sqrt(x)。
-
对数函数:log(x)、log2(x)。
-
三角函数:sin(x)、cos(x)、tan(x)。
-
反三角函数:asin(x)、acos(x)、atan(x)。
-
-
LD/ST:加载/存储模块(Load/Store)。辅助一个Warp(线程组)从Share Memory或显存加载(Load)或存储(Store)数据。
-
Register File:寄存器堆。存放将要处理的数据。
-
L1 Cache:L1缓存。不同GPU架构不一样,有些L1缓存和Shared Memory共用,有的L1缓存和Texture Cache共用。
-
Uniform Cache:全局统一内存缓存。
-
Tex Unit和Texture Cache:纹理读取单元和纹理缓存。Fermi有4个Texture Units,每个Texture Unit在一个运算周期最多可取4个采样器,这时刚好喂给一个线程束(Warp)(的16个车道),每个Texture Uint有16K的Texture Cache,并且在往下有L2 Cache的支持。
-
Interconnect Network:内部链接网络。
GPU内存架构
GPU类似于CPU也有自己的寄存器、L1 Cache、L2 Cache、显存,甚至必要时候还可以使用系统内存。
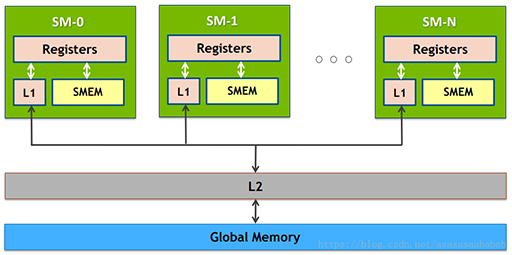
图中越往上,存取速度越快,越往下存取速度越慢。其中,Global Memory(全局内存)即我们通常所说的显存,通常放在GPU芯片的外部。L2 Cache是GPU芯片内部跨GPC而存在的。L1 Cache/Shared Memory、Uniform Cache、Tex Unit和Texture Cache以及寄存器都是存在于SM内部的。
它们的存取速度从寄存器到全局内存依次变慢:
| 存储类型 | 访问周期 |
|---|---|
| 寄存器 | 1 |
| 共享内存 | 1~32 |
| L1缓存 | 1~32 |
| L2缓存 | 32~64 |
| 纹理、常量缓存 | 400~600 |
| 全局内存 | 400~600 |
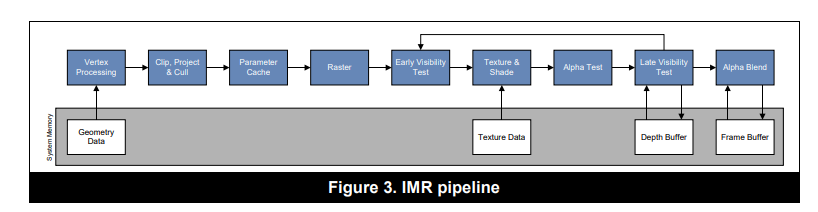
GPU架构和渲染管线
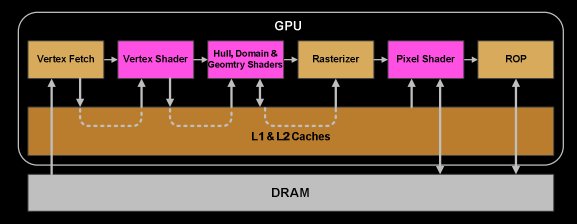
如果从GPU硬件的视角下来看渲染管线,会看到一些不一样的东西,下图为GPU硬件视角下的渲染管线概要。
应用阶段
这个阶段主要是CPU在准备数据,包括图元数据、渲染状态等,并将数据传给GPU的过程。如下图所示就是数据如何进入GPU处理的过程。
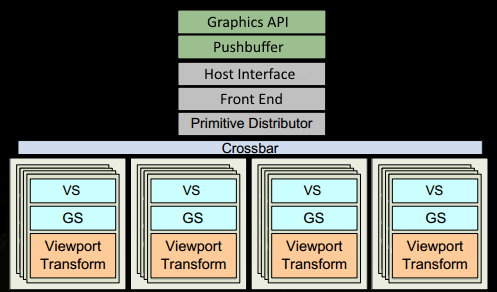
CPU和GPU之间的数据传输是一个异步的过程,类似于服务器和客户端之间的数据传输。CPU和GPU构造了一种生产者/消费者异步处理模型。CPU生产“命令”,GPU消费“命令”,通过这种关系CPU就可以将数据和行为传输到GPU,GPU来执行对应动作。
CPU端通过调用渲染API(Graphics API),比如DX或者GL,将操作封装为一个一个的命令存放到命令队列中(FIFO Push Buffer),即上图中的PushBuffer。
当内存写满或者显示调用(Present或者Flush等)提交命令队列的时候,CPU将命令队列提交给应用驱动,并在命令队列末尾压入一条改变Fence值的命令。
接下来,通过系统驱动的调度,轮到这个应用传输的时候,就将数据写入到内存中的RingBuffer中。RingBuffer好比一个旋转的水车,将命令一点一点“搬运”到GPU的前端(Front End)。当这个“水车”满了,也就是RingBuffer满了,CPU就会发生拥塞。
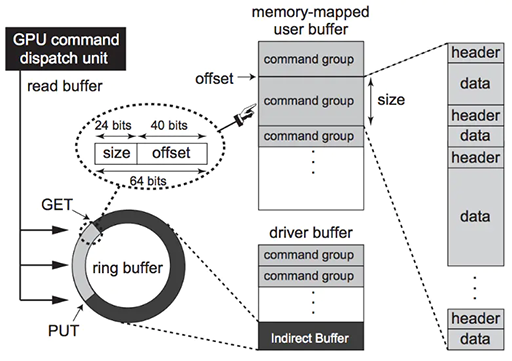
当命令队列最后一条命令,也就是修改Fence值的命令被前端接收后,CPU接到了Fence修改的信号,拥塞就会被解除,CPU继续运行产生接下来的命令。
图元装配器(Primitive Distributor)根据图元类型、顶点索引以及图元装配命令,开始分配渲染工作,并发送给多个GPC处理。
顶点处理
PolyMorph Engine的Vertex Fetch模块通过三角形索引,将数据从显存中取得三角形数据,传入SM寄存器中。
前文说过Shader就是在SM上进行处理的。熟悉Shader开发的人都知道,Shader会对不同的“语义”进行处理,这些语义也叫“寄存器”。Shader中使用到的寄存器不光这些“语义”的寄存器,它们分为很多种类型,包括输入寄存器、常量寄存器、临时寄存器等。
| Shader Model 2.0/2.X | Shader Model 3.0 | Shader Model 4.0 | |
|---|---|---|---|
| 临时寄存器 | ≥12 | 32 | 4096 |
| VS常量寄存器 | ≥256 | ≥256 | 14×4096 |
| PS常量寄存器 | 32 | 224 | 14×4096 |
| VS纹理 | None | 4 | 128×512 |
| PS纹理 | 16 | 16 | 128×512 |
| VS输入寄存器 | 16 | 16 | 16 |
| 插值寄存器 | 8 | 10 | 16/32 |
| PS输出寄存器 | 4 | 4 | 8 |
数据进入SM后,线程调度器(Warp Scheduler)为每个Shader核心函数(VS/GS/PS等)创建一个线程,并在一个运算核心(Core)上执行该线程。根据Shader需要的寄存器数量,在寄存器堆(Register File)中为每个线程分配指定数量的寄存器。
同时,指令调度单元(Instruction Dispatch Unit)将Shader中的操作指令从指令缓存(Instruction Cache)中取出,并分配给每个运算核心去执行。
对于Shader的这种处理机制,不管是VS(Vertex Shader)还是PS(Pixel Shader),以及GS(Geometry Shader)等着色器来说都是相同的。换句话说,就是无论VS、PS、GS,都是在SM的运算核心里执行每一条指令的。
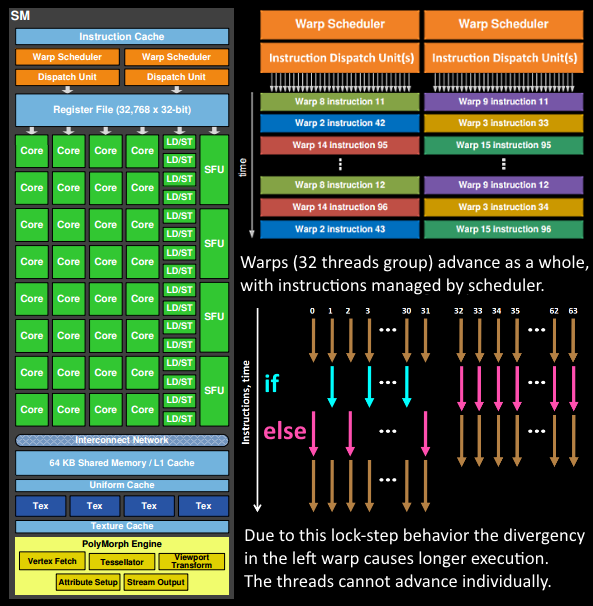
那么要深入理解SM工作的这种机制,这里需要解释一下三个重要的概念:统一着色器架构、SIMT和线程束。
统一着色器架构
Shader Model 在诞生之初就为我们提供了Pixel Shader(顶点着色器)和Vertex Shader(像素着色器)两种具体的硬件逻辑,它们是互相分置彼此不干涉的。
但是在长期的开发过程中,发现了以下的问题。
-
如果一个场景包含的三角形相当细碎,那么这个为了渲染这个场景,顶点着色器的处理单元就会负载很高,但是会有很大一部分像素着色器的处理单元闲置。
-
如果一个场景仅包含一个大的三角形,而且这个大三角形覆盖了大部分的屏幕像素且运算很复杂,那么像素着色器的处理单元就会负载很高,但是会有一大部分顶点着色器的处理单元闲置。
下图展示了Vertex Shader和Pixel Shader的负载对比。
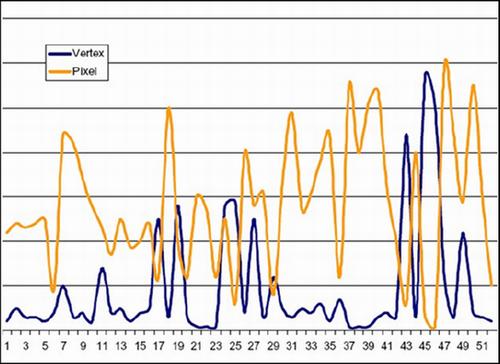
在长期的发展过程中,NVIDIA和ATI的工程师都认为,要达到最佳的性能和电力使用效率,还是必须使用统一着色器架构才能解决上述问题。
在统一着色器架构的GPU中,Vertex Shader和Pixel Shader概念都将被废除,取而代之的就是“运算核心(Core)”。运算核心是个完整的图形处理体系,它既能够执行对顶点操作的指令(代替VS),又能够执行对象素操作的指令(代替PS)。GPU内部的运算核心甚至能够根据需要随意切换调用,从而极大的提升游戏的表现。
SIMT
前文提到指令(Instruction)会经过调度单元(Dispatch Unit)的调度,分配到每一个运算核心去执行。
那么,指令是什么呢?其实指令可以理解为一条一条的操作命令,也就是告诉运算核心要怎么做的“描述语句”。比如 “将tmp25号寄存器里的值加上tmp26号寄存器里的值,得到的值存入tmp27号寄存器”这种操作,就是一条指令。
调度单元这里分配给每一个运行核心去执行的指令其实都是相同的。也就是说调度单元(Dispatch Unit)让每个运算核心在同一刻干的事情都是一样的。每一个运算核心虽然同一时刻做的操作是一样的,但是它们所操作的数据各自都是不同的。
举个例子,还是上面的这条指令——“将tmp25号寄存器里的值加上tmp26号寄存器里的值,得到的值存入tmp27号寄存器”。对于A运算核心和B运算核心来说,它们各自的tmp25号、tmp26号寄存器里存的值都是不一样的,以下为两个核心可能出现情况的例子。
-
对于A运算核心来说,tmp25号存了“2”,tmp26号存了“3”,最终计算后写入tmp27号寄存器的数是“5”。
-
对于B运算核心来说,tmp25号存了“8”,tmp26号存了“12”,最终计算后写入tmp27号寄存器的数是“20”。
这就是SIMT(Single Instruction Multiple Threads),T(线程,Threads)对应的就是运算核心(下文会介绍),翻译过来叫做“单指令多线程(运算核心)”,顾名思义,指令是相同的但是线程却不同。
通过上文的解释,我们还了解到了运算核心执行指令的另一个特征:运算核心执行指令的方式叫做“lock-step”。也就是所有运算核心同一时间执行的指令都是相同的,只有所有核心执行完当前指令,调度单元(Dispatch Unit)才会分配下一条指令给所有运算核心执行。
线程束
每个SM包含了很多寄存器,每个Shader核心函数(VS/GS/PS等)会当作一个线程去执行。Shader经过编译后,可以明确知道要执行的核心函数需要多少个寄存器,也就是说每个线程需要多少个寄存器是明确的。当线程要执行时,会从寄存器堆上分配得到这个线程需要数目的寄存器。比如一个SM总共有32768个寄存器,如果一个线程需要256个寄存器,那么这个SM上总共可以执行32768/256=128个线程。
SM上每一个运算核心同一时间内执行一个线程,也就是说一个线程其实是对应一个运算核心,但是,一个运算核心却是对应多个线程。这该怎么理解呢?
上文说到Shader所需要的寄存器数量决定了SM上总共能执行多少个线程。一个SM上总共也就有32个运算核心,但是如果多于32个线程需要执行怎么办?
线程调度器会将所有线程分为若干个组,每一个组叫做一个线程束(Warp),它又包含了32个线程。因此如果一个SM总共有32768个寄存器,这个SM总共可以执行128线程,那么这个SM上总共可以分配128/32=4个线程束。
一个运算核心同一时间只能处理一个线程,一组(32个)运算核心同一时间只能处理一个线程束,而线程束中有些指令处理起来会比较费时间,特别是内存加载。每当当前线程束(Warp)遇到费时操作,它就会被阻塞(Stall)。为了降低延迟,GPU的线程调度器会采用一种简单而有效的策略,就是切换另一组线程来运行。
运算核心在多个线程束(Warp)间切换着执行,最大化利用运算资源,也就解释了上文中所描述的线程和运算核心之间的关系了。
下图展示了一个SM执行三个线程束的例子。例子中一个线程束只有4个线程是一种简化图形的表示方式,根据上文可知,其实一个线程束中的线程数远大于4。下图中的txr指令延迟会比较高,所以容易使线程阻塞(Stall)。
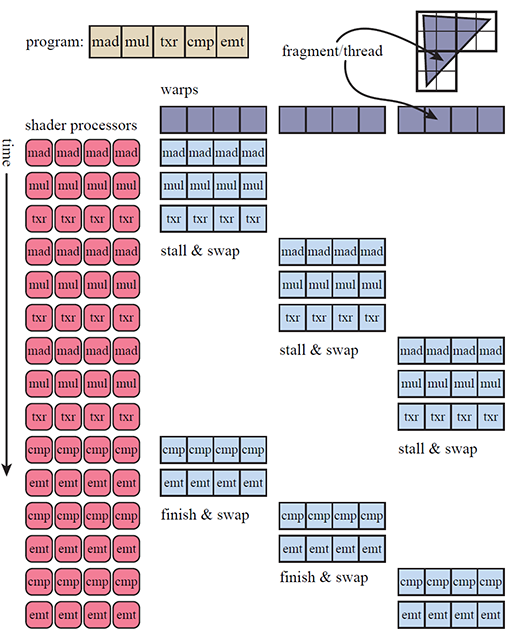
细心的你如果仔细思考,也许会产生一个疑问:为什么线程调度器不去调度线程而是调度线程束?
通过上一小节介绍“SIMT”的时候我们了解到运算核心是以lock-step的方式执行的,也就是说线程执行的“步调”是一致的,每条指令对于所有线程来说都是“一起开始一起结束”。所以线程调度器调度的单位是线程束(Warp)。
由于线程束的机制,可以推出以下结论。由于寄存器堆的寄存器数量是固定的,如果一个Shader需要的寄存器数量越多,也就是每个线程分配到的寄存数量越多,那么线程束数量就越少。线程束少,供线程调度器调度的资源就少,当遇到耗时指令时,由于没有更多线程束去灵活调配,所有线程就只能死等,不利于资源的充分利用,最终导致执行效率低下。
裁剪空间
当Warp完成了VS的所有指令运算,就会被PolyMorph Engine的Viewport Transform模块处理,并将三角形数据存放到L1和L2缓存里面。此时的三角形会被变换到裁剪空间(Clip空间),在这个空间下的顶点为像素处理阶段做好了准备。
像素处理
为了平衡光栅化的负载压力,WDC(Work Distribution Crossbar)会根据一定策略,将屏幕划分成多个区域块,并重新分配给每一个GPC。下图为WDC为屏幕划分区域块的示意图。
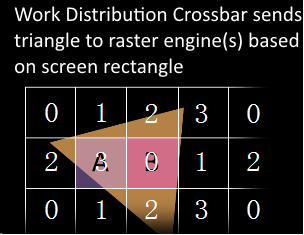
前文提到GPC里有一个光栅化引擎(Raster Engine),这里GPC接收到分配的任务后,就是交给光栅化引擎来负责这些三角形像素信息的生成。同时还会处理其他的一些渲染流水线步骤,包括裁剪(Cliping)、背面剔除以及Early-Z。
接下来光栅化引擎将插值好的数据转交给PolyMorph Engine的Attribute Setup模块,将Vertex Shader计算后存放在L1和L2缓存里面的数据加载出来,经过插值的数据填充到Pixel Shader的寄存器里,供SM的运算核心做像素计算的时候使用。
在逻辑上,一个线程执行一个Pixel Shader的核心函数,也就是一个线程处理一个像素。GPU将屏幕分成一个一个的2×2的像素块,因为逻辑上一个Warp包含了32个线程,也就是说一个Warp处理的是8个像素块。
上文提到WDC会根据一定策略划分区域块,实际上的划分可能比上图更加复杂。网上有博主根据NV shader thread group提供的OpenGL扩展,基于OpenGL 4.3+和Geforce RTX 2060做了如下实验。
首先,应用程序画了两个覆盖全屏的三角形。顶点着色器就不赘述了,下面看看片元着色器。
#version 430 core
#extension GL_NV_shader_thread_group : require
uniform uint gl_WarpSizeNV; // 单个线程束的线程数量
uniform uint gl_WarpsPerSMNV; // 单个SM的线程束数量
uniform uint gl_SMCountNV; // SM数量
in uint gl_WarpIDNV; // 当前线程束id
in uint gl_SMIDNV; // 当前线程所在的SM id,取值[0, gl_SMCountNV-1]
in uint gl_ThreadInWarpNV; // 当前线程id,取值[0, gl_WarpSizeNV-1]
out vec4 FragColor;
void main()
{
// SM id
float lightness = gl_SMIDNV / gl_SMCountNV;
FragColor = vec4(lightness);
}
渲染画面如下图所示。

图中有32个亮度色阶也就说明有32个不同编号的SM,由渲染结果可以看到SM的划分并不是按编号顺序简单地依次划分的。另外根据上图可见,同一个色块内的像素分属不同三角形,就会分给不同的SM进行处理。如果三角形越细碎,分配SM的次数就会越多。

这里一个色块是16×16,也就说明一个SM里运行了256个线程。
将片元着色器改为如下代码,显示Warp的分布情况。
// warp id
float lightness = gl_WarpIDNV / gl_WarpsPerSMNV;
FragColor = vec4(lightness);
渲染画面如下图所示。
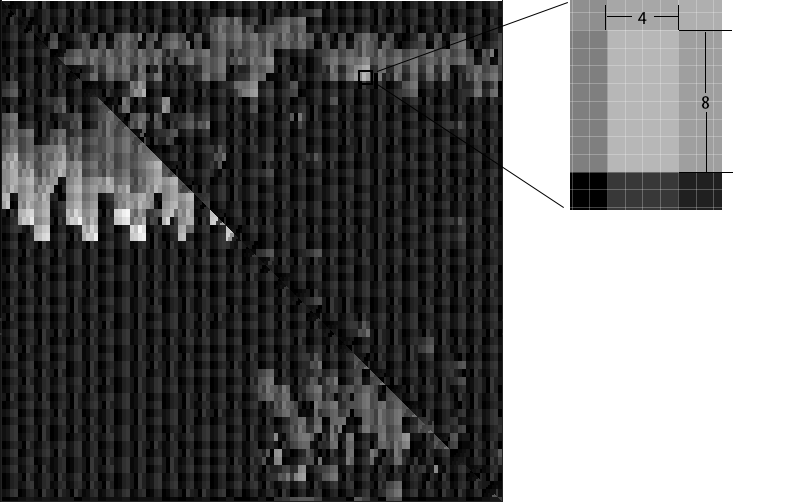
由于一个色块是由4×8个像素组成,也就证明了一个Warp包含了32个线程。
输出到渲染目标
经过PS计算,SM将数据转交给Crossbar,让它分配给ROP(渲染输出单元)。像素在这里进行深度测试以及帧缓冲混合等处理,并将最终值写入到一块FrameBuffer里面,这块FB就是双缓冲技术里面的后备缓冲。最终将FB写入到显存(DRAM)里。

多平台渲染架构
关于IMR、TBR、TBDR介绍的文章有很多,下面简单归纳一下。
IMR
IMR架构主要是PC上GPU采用的渲染架构,这个架构主要是渲染快、带宽消耗大。
特点:
-
每一个Drawcall按顺序、连续地执行完成。每一个Drawcall从VS、PS到最终写入FrameBuffer中的颜色缓冲、深度缓冲,中间没有打断。
-
FrameBuffer可以被多次访问。也就是说每个Drawcall的每像素渲染都会直接写入FrameBuffer。
-
每个像素频繁访问显存上的FrameBuffer,带宽消耗大。
IMR模式的GPU执行的伪代码如下。
for (draw in renderPass)
{
for (primitive in draw)
{
execute_vertex_shader(vertex);
}
if (primitive is culled)
break;
for (fragment in primitive)
{
execute_fragment_shader(fragment);
}
}
问题:
-
发热量大。主要是带宽消耗大导致的,这个在PC上没有太大问题。
-
耗电量大。主要是带宽消耗大导致的,这个在PC上没有太大问题。
-
芯片大小大。这个在PC上没有太大问题,为了优化带宽会有L1 Cache和L2 Cache,所以芯片会变大。
TBR
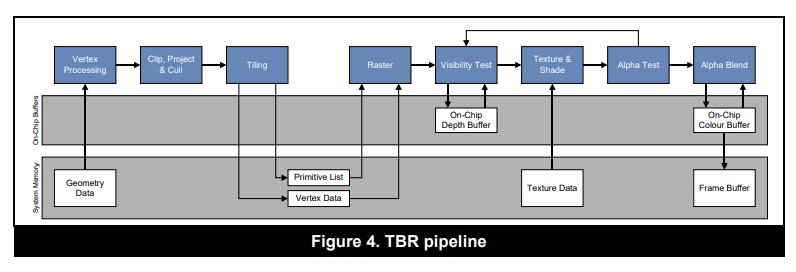
TBR全称Tile-Based Rendering,是一种基于分块的渲染架构。
分析:
-
发热、费电,移动设备接受不了。
-
芯片太大,移动设备接受不了。
为了解决以上IMR的问题,移动设备上的芯片采用了不一样的设计思路:不直接往显存的FrameBuffer里写入数据,而是将屏幕分成小块(Tile),每一个小块数据都存在On Chip Memory(类似L1和L2的缓存)上,合适的时候一次性渲染并将所有分块数据从On Chip Memory写入显存的FrameBuffer里。
由于不会频繁写入FrameBuffer,带宽消耗降低了,发热、耗电量问题都解决了;由于分块写入高速缓存On Chip Memory,芯片大小问题解决了。
特点:
-
每一个Drawcall执行时仅仅经过分块(Tiling)和顶点计算,存入FrameData。“合适”的时机(如Flush、clear)进行Early-Z、着色、各种测试,最终一次性写入FrameBuffer中的颜色缓冲、深度缓冲,中间过程是不连续。
-
FrameBuffer访问次数很少,FrameData会被频繁访问。
-
由于分块(Tile)的颜色缓冲和深度缓冲会放到On Chip Memory上,Early-Z和Z-Test都在这上面进行,节省带宽。
TB(D)R模式的GPU执行的伪代码如下。
// Pass one
for (draw in renderPass)
{
for (primitive in draw)
{
for (vertex in primitive)
{
execute_vertex_shader(vertex);
}
if (primitive not culled)
{
append_tile_list(primitive);
}
}
}
// Pass two
for (tile in renderPass)
{
for (primitive in tile)
{
for (fragment in primitive)
{
execute_fragment_shader(fragment);
}
}
}
TBDR
TBDR全称Tile-Base-Deffered Rendering,是一种基于分块的延迟渲染架构。
分析:
- Early-Z可以很好的降低Overdraw,但是TBR依赖物体绘制顺序。如果物体循环遮挡,无法完美地做到降低Overdraw。
PowerVR设计了一个叫做ISP(Image Signal Processor)的处理单元,不依赖物体从远到近绘制,而是对图形做像素级的排序,完美通过像素级Early-Z降低Overdraw,这种技术称为HSR(Hidden Surface Removal)。
类似的技术比如:Adreno的Early Z Rejection,Mali的FPK(Forward Pixel Killing)。
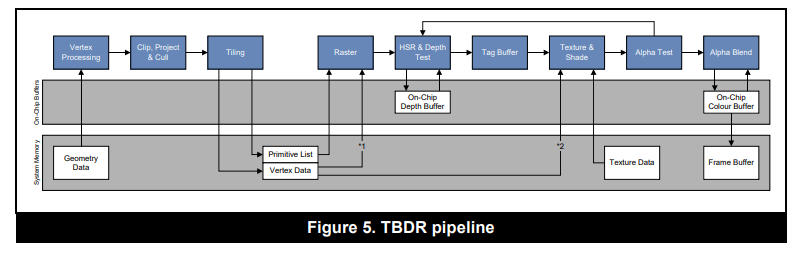
相关渲染优化
寄存器充分使用
前文提到过,如果寄存器使用过多,会导致Warp数量变少,使得GPU遇到耗时操作的时候没有空闲Warp去调度,不利于GPU的充分利用,因此要节约使用寄存器。
对于Shader的语义也好,寄存器也好,都是作为矢量存在的。对于GPU的ALU来说,一条指令可以处理的数据一般是四维(4D)的,这就是SIMD(Single Instruction Multiple Data),类似的SIMD指令可以参考SSE指令集。
例如下面的代码。
float4 c = a + b;
如果没有SIMD处理单元,汇编伪代码如下,四个数据需要四个指令周期才能完成。
ADD c.x, a.x, b.x
ADD c.y, a.y, b.y
ADD c.z, a.z, b.z
ADD c.w, a.w, b.w
而使用SIMD处理后就变为一条指令处理四个数据了,大大提高了处理效率。
SIMD_ADD c, a, b
由于SIMD的特性,寄存器要尽可能完全利用。例如Unity里有一个宏用来缩放并且偏移图片采样用的UV坐标——TRANSFORM_TEX。按道理缩放UV需要乘以一个二维向量,偏移UV也需要加一个二维向量,这里应该是需要两个寄存器的。然而Unity将两个二维向量都装入同一个四维向量里面(xy为缩放,zw为偏移),这样就只用到一个寄存器了。总而言之,要充分利用寄存器向量的每一个分量。其定义如下。
// Transforms 2D UV by scale/bias property
#define TRANSFORM_TEX(tex,name) (tex.xy * name##_ST.xy + name##_ST.zw)
为了充分利用SIMD运算单元,GPU还提供了一种叫做co-issue的技术来优化代码。例如下图,由于float数量的不同,ALU利用率从100%依次下降为75%、50%、25%。
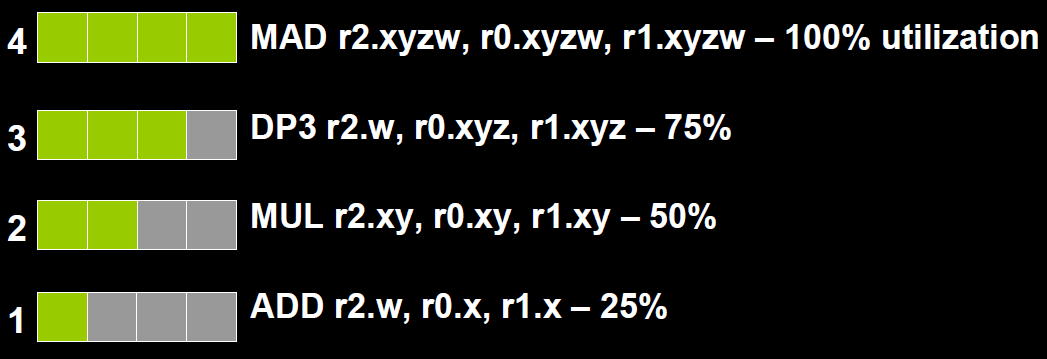
为了解决着色器在低维向量的利用率低的问题,可以通过合并1D与3D或2D与2D的指令。例如下图,原本的两条指令,co-issue会自动将它们合并,这样一个指令周期就可以执行完成。
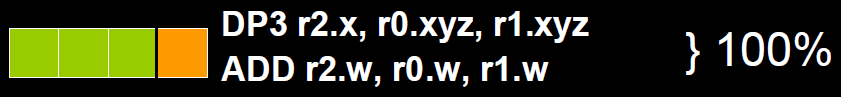
但是如果其中一个变量既是操作数,又是存储数,则无法启用co-issue来优化。

于是标量指令着色器(Scalar Instruction Shader)应运而生,它可以有效地组合任何向量,开启co-issue技术,充分发挥SIMD的优势。
逻辑控制语句
GPU和CPU由于其设计目标就有很大的区别,于是出现了非常不同的架构。
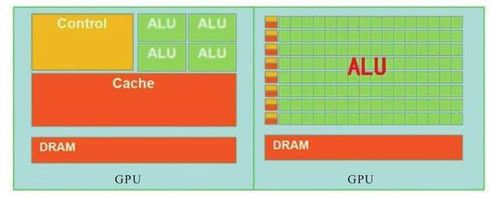
CPU有大量的存储单元(红色部分)和控制单元(黄色部分),相比起GPU来说,CPU的计算单元(绿色部分)只占了很少一部分。因此CPU不擅长大规模并行计算,更擅长于逻辑控制。相反,GPU擅长大规模并行计算,不擅长逻辑控制。
因此,不要在Shader里写逻辑控制语句,包括if-else和for循环等逻辑。下面介绍一下两种芯片在分支控制上都有哪些区别。
CPU - 分支预测
有人在JVM上做过一个测试。如果有一个有序数组,和一个同样大的无序数组,分别取出一百万次其数组中大于128的数字之和,消耗的时间是否相同呢?
long long sum = 0;
for (unsigned i = 0; i < 1000000; ++i)
{
for (unsigned c = 0; c < arraySize; ++c)
{
if (data[c] >= 128)
sum += data[c];
}
}
以上这段代码,按实验步骤来做。
-
第一次data数组是个无序数组,消耗时间为18.7739秒,sum = 312426300000。
-
第二次data数组事先给排好序,消耗时间是5.69566秒,sum = 312426300000。
两次实验数据数量、循环次数以及实验算出来的最终结果都是一样的,为何两次消耗时间相差竟有3倍之多?要了解这个问题,就需要了解CPU的分支预测了。
一条指令在CPU上执行,需要经过以下四个步骤:
-
fetch(获取指令)
-
decode(解码指令)
-
execute(执行指令)
-
write-back(写回数据)
比较笨一点的办法就是,每一条指令等上一条的这四步都走完再执行。显然这样效率不是很高,其实当一条指令开始执行第二步decode时,下一条指令就可以开始执行第一步fetch了。同理,当一条指令开始执行execute,下一条指令就可以执行decode了,再下一条指令就可以执行fetch了。
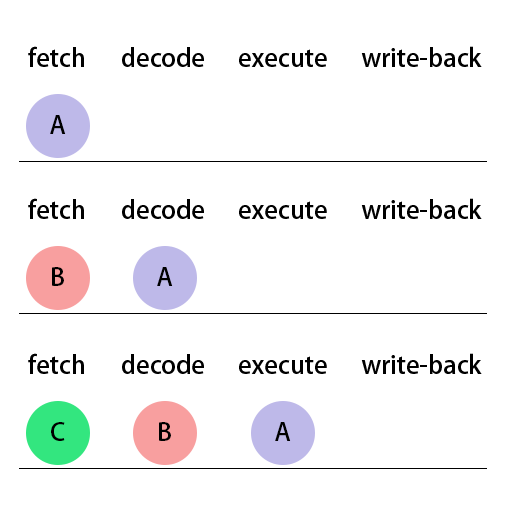
那么如果if指令已经执行到decode了,接下来该执行if语句块里面的指令,还是该执行else语句块里面的指令,CPU还不知道,因为只有if条件判断执行完成才能知道接下来该执行哪个语句块里的指令。

此时,CPU会先尝试将上一次判断的历史记录拿来这一次作为判断条件来先用着,这就是所谓的“分支预测”。如果预测对了,那么对于性能来说就是赚了;如果预测错误,那么就从fetch开始用正确的值重新来执行,也不亏性能。
GPU - 遮掩
GPU讲究的是大规模并行计算,没有那么强大的逻辑控制,所以GPU也不会去做分支预测。那么GPU是怎么去处理条件分支判断的呢?
由于GPU的执行是以lock-step的方式锁步执行的,也就是每一个运算核心一定要执行完当前指令的所有步骤才能执行下一条指令,也就是前文中所说的“比较笨一点的办法”,所以GPU是没有分支预测的。但是GPU有一个特殊的机制叫做遮掩(mask out)。
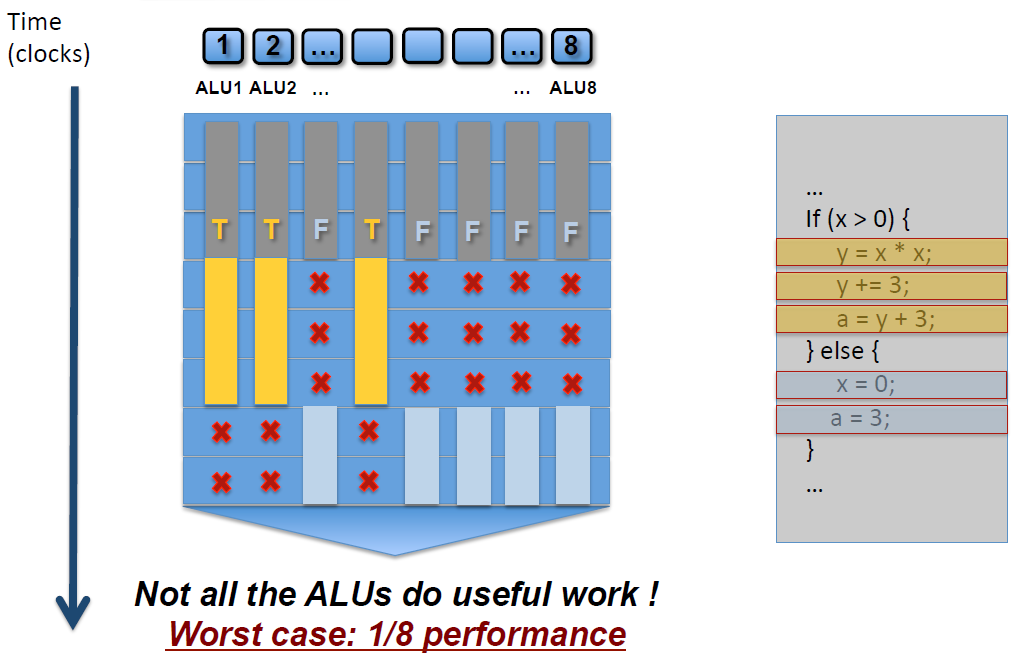
如上图所示,同时有8个线程在执行右边代码的指令。有的线程满足x大于0,那么左图中黄色部分就会被执行,但是同一指令周期内,其他的线程x小于或等于0,这些线程的指令就会被遮掩,也就是虽然也是要消耗时间,但是不会被执行,就处于了等待。同理,满足else条件的语句在接下来的指令执行周期内执行浅蓝色部分,不满足的在同一指令周期内就被遮掩,处于等待。
被遮掩的代码同样是要消耗相同的指令周期时间去等待未被遮掩的代码执行。因此,如果一个Shader里有太多的if-else语句,就会白白浪费很多时间周期。
同样的原理应用在for循环上,如果有的线程循环3遍,有的线程循环5遍,就需要等待循环最久的那个线程执行完成才能继续往下执行,造成很多线程的浪费。
因此,在Shader中不是不能写逻辑控制语句,而是要思考一下有没有被浪费的资源。换句话说,Shader里不要用不固定的数值来控制逻辑执行。
减少调用费时指令
通常一些需要从缓存里,甚至内存里读取数据的操作会比较费时,例如贴图采样的指令。
从上文中可以了解到,一般GPU架构里SFU这种处理单元比较少,因此特殊数学函数尽量少调用,例如pow、sin、cos等。
移动渲染架构的优化
及时clear或者discard
由于TB(D)R架构下数据会一直积攒到FrameData里,直到“合适”的时机才会清空。如果一直不调用clear指令就会一直将数据积累到FrameData里清不掉。如果不用RenderTexture了就及时Discard掉。
例如有一张RenderTexture,渲染之前调用clear就能清空前一次的FrameData,不用这张RenderTexture了,就及时调用Discard(),以提高性能。
不要频繁切换RenderTexture
频繁切换RenderTexture会导致频繁将Tile数据拷贝到FrameBuffer上,增加性能消耗。
Early-Z
Early-Z可以很好的降低Overdraw,但是某些操作会使Early-Z失效。
-
Alpha Test / Clip / discard:需要执行完 PS 后,才能确定该像素深度是否被写入。
-
手动修改GPU插值得到的深度。
-
开启透明混合(AlphaBlend)。
-
关闭深度测试。
特别说明:因为Early-Z是通过深度去屏蔽不透明物体的,如果透明物体(Alpha Blend)或者挖洞的物体(Alpha Test)通过深度测试屏蔽了背景的不透明(Opaque)物体,那么背景就会镂空,看到clear指令指定的固有色,就会出现渲染错误,因此无论IMR还是T(D)BR的Early-Z都会受Alpha Test影响。
因此要做到以下几点。
-
渲染物体时,渲染程序要按“Opaque → AlphaTest → AlphaBlend”的顺序渲染物体。
-
由于一般来说地形覆盖面积最大,“Opaque”的内部可以按“其他不透明物件 → 地形”的顺序渲染,最大化利用Early-Z优化Overdraw。
-
无论PowerVR还是Mali/Adreno芯片,AlphaTest都会影响性能,尽量少使用AlphaTest技术。
-
不支持Early-Z的硬件,可以适当使用PreDepathPass多渲染一遍图元来优化Overdraw,但是会增加顶点绘制的负担,需要权衡。
避免大量drawcall和顶点数
FrameData里会储存当前帧变换过的图元列表,也就是顶点数据,FrameData数据会随着Drawcall数增加而增加,FrameData增大有可能会存储到其他地方,影响读写速度,因此在移动平台渲染上百万个顶点或者三四百Drawcall就比较吃力了。
总结
本文主要归纳了GPU内部的一些基本单元及其作用,简单总结了一下对渲染架构的描述,并针对以上两方面介绍了一些优化性能的技巧。本文更多是归纳总结性质的,如果要更加深入的了解可以细读以下参考文章。
参考
《Life of a triangle - NVIDIA’s logical pipeline》(翻译)